Lecture 1: Welcome to Statistics!#
Stanford University Spring 2025
Instructor: Professor Tselil Schramm
What is statistics?#
Statistics: the science of drawing conclusions from data.
We need statistics to
Make good decisions (medicine, funding/resource allocation, focus groups, design choices)
Make accurate predictions (weather, political forecasting, autocorrect, AI models)
Understand the physical world (biology, chemistry, physics, engineering)
Statistics in medicine#
Statistics is crucial for deciding if a medical treatment is effective. A classic example is the Salk polio vaccine trial.^[Source: @meier1972biggest]
Through the 1950’s, Polio was one of the most feared childhood diseases in the U.S.
The disease was pretty rare, affecting about 50 in 100,000 (comparison: on average, 2 / 4,000 Stanford undergrads would have had the disease).
The disease struck hardest in wealthy areas with good sanitation.
The disease was also unpredictable; different cities experienced waves on different scales from year to year.
If a kid got sick, the outcomes could be really bad: a reasonable fraction were paralyzed for life, and some even died.
How should we run a vaccine trial?#
In the early 1950’s, Jonas Salk develops a vaccine. The vaccine is an inactive vaccine: it is made of Polio virus that has been killed with formaldehyde.
Pros of an inactive vaccine: less likely to cause infection
Cons of an inactive vaccine: less likely to cause immunity
To determine whether the vaccine was effective, statisticians and doctors had to design a trial.
What are some challenges in designing such a trial? How would you go about it?
Salk polio vaccine trial#
The Salk polio vaccine trial took place in 1955. There were two experiments: one observational study and one randomized double blind.
Randomized double blind study#
Group |
Size |
Rate |
|---|---|---|
Treatment |
200,000 |
28 / 100,000 |
Control |
200,000 |
71 / 100,000 |
No Consent |
350,000 |
46 / 100,000 |
Observational study#
Group |
Size |
Rate |
|---|---|---|
Grade 2 (vaccine) |
225,000 |
25 / 100,000 |
Grades 1 and 3 (control) |
725,000 |
54 / 100,000 |
No Consent |
125,000 |
44 / 100,000 |
How strong is the evidence in the double blind study?
Statistics gives an answer! Theory suggests that there’s a \(\ge 90\%\) chance that the double-blind experiment rates are within \(20\%\) of the “true” rates.
How does the observational study compare to the double blind experiment?
Statistical thinking suggests sample bias could be a problem in the observational study.
Statistics in business and politics#
A/B testing is used widely in business and in politics to determine what the consumers/voters prefer.
Scenario: you have two options, A or B, for how to advertise/design a product.
Example: should the homepage of the Obama campaign use the word “sign up” or “learn more” for the mailing list link?
Idea: run an experiment.
Each user is randomly assigned into group A or B (and then given product A or B).
See if option A or B generates a more favorable response.
There are many famous stories about how decisions made through A/B testing dramatically increased revenue/engagement.
For example, the 2008 Obama campaign used A/B testing extenstively. The “learn more” vs. “sign up” button + a photo tweak increased mailing list sign ups 40%.
Microsoft Bing A/B tested the perfect shade of blue for links, leading to increased user engagement and tens of millions in increased annual revenue.
Have you yourself experienced A/B testing? E.g. you notice you have access to a different app feature than your friends.
Statistics in sports#
“Moneyball”: baseball teams used to choose draft picks based on vibes.
Starting around 2001, the Oakland A’s started picking players based on stats.


Now, everyone does this.
Statistics and data in designing AI models#
An old idea in statistics is to use data to “train a model.”
This means you find patterns in the data, and use them to make predictions.
The simplest example is a linear regression.

Modern AI models#
Modern AI models are nothing but (more sophisticated) statistical models, fit to a mind-blowing amount of data. ^[Caveat: statistical principles are used to engineer AI models. But we still lack statistical tools for quantifying legitimacy of AI-found patterns. This is a frontier of statistical research!]
Image source: NVIDIA
Starting in early 2010’s, advances in computing power and model design have taken this pattern finding to an astounding level.
Relatedly, generative AI is, at its core, an example of the classic statistical problem of “density estimation” or “sample generation.”
Mistakes and Misuses of Statistics#
Statistics is a set of tools, whose validity is based on logic and mathematical modeling.
Applied properly, Statistics lets us draw useful conclusions from data.
Applied incorrectly, it can cause us to draw incorrect conclusions from data!
Like any tool, it’s dangerous to blindly trust statistics!
Classic Mistake: the prosecutor’s fallacy#
-
In 1995, retired football star O.J. Simpson stood trial for the murder of his ex-wife.
The prosecution presented evidence that O.J. had been violent towards his wife during their marriage. In defense, O.J.’s lawyers used the following argument:
”Less than 1 in 2500 women who is domestically abused by her spouse is later murdered by her spouse.”
What is more relevant is the following fact:
”8 out of 9 domestically abused women who are murdered are murdered by their spouse.”
The prosecution’s argument is a misapplication of probabilistic logic. Most women who are abused by their spouse are not murdered, but most abused women who are murdered are murdered by their spouse.
Similar issues occur in testing for rare diseases.
If you get tested for a disease which occurs in \(\le 1\%\) of the population using a test that is \(99\%\) accurate, there is a \(\ge 50\%\) chance that a positive result is a false positive!
Mistake: spurious correlations and p-hacking#
The scientific method demands that we first make a hypothesis, then collect data, and only then decide whether to reject the hypothesis.
If we collect data first, and look for patterns afterwards, we risk drawing false conclusions. For example,

Source: Tyler Vigen
Imagine you are a scientist, and you have been collecting data in your lab during an experiment that lasts several months. Your data does not allow you to confidently reject your original hypothesis. What are statistically sound ways to analyze your data?
A misunderstanding of the statistical underpinnings can lead to accidental “p-hacking.”
Mistake: sample bias#
Polling, especially on controversial issues, is tricky.
If you collect a non-uniform sample, your answer can be systematically skewed!
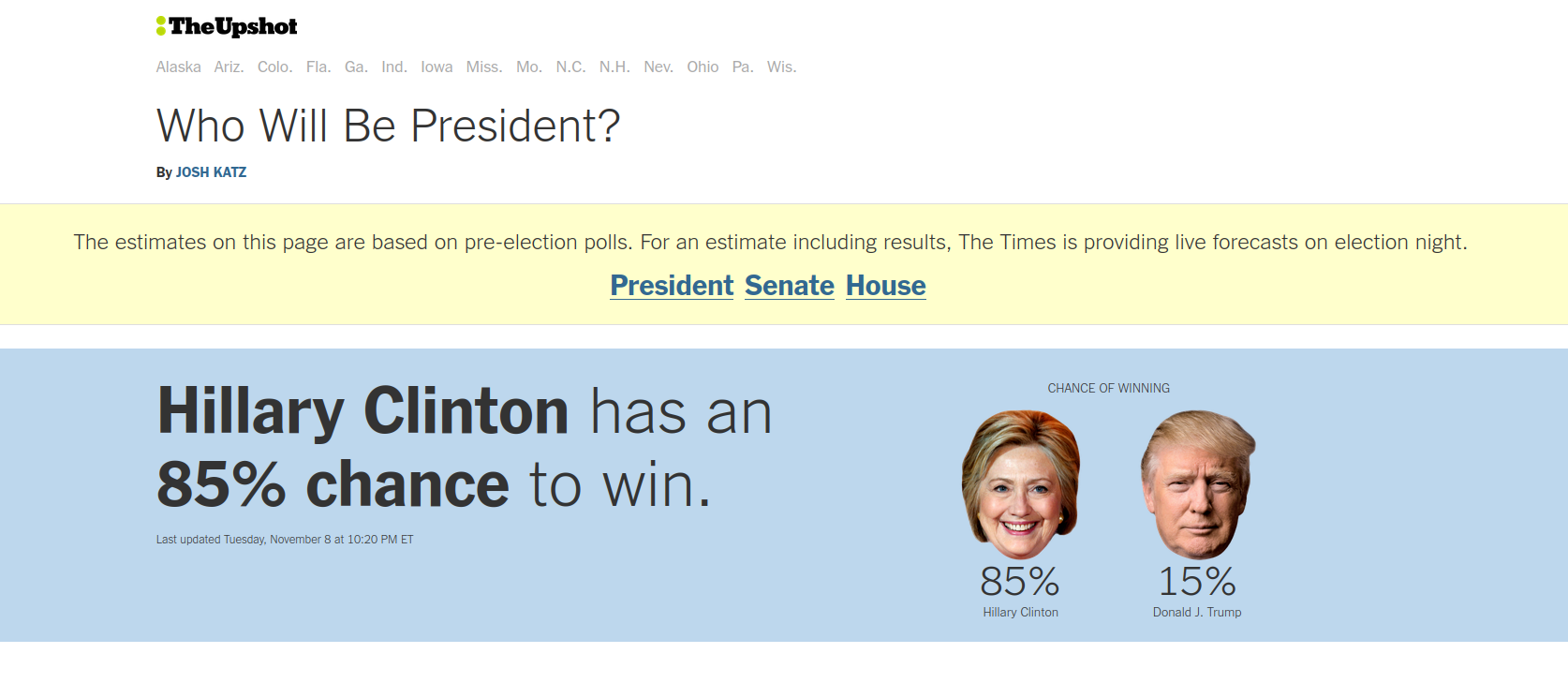
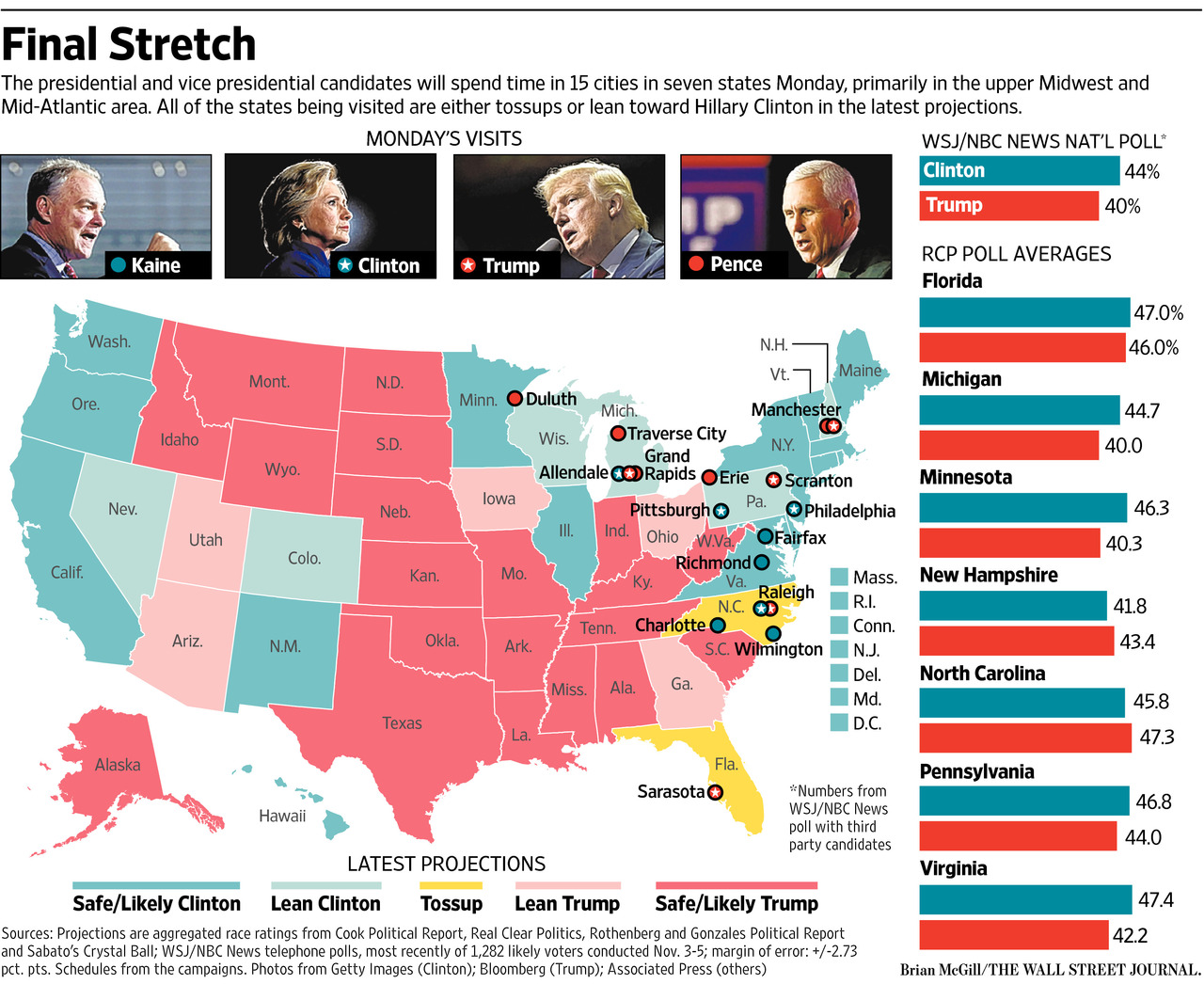
The same phenomenon occurs when you are trying to estimate any quantity, e.g. average income, average height, effectiveness of a medication, danger of a sport.
Empowerment through learning!#
The main goal of this class is to empower you with the basics of statistics and statistical thinking. We want you to:
Understand numerical and statistical concepts for yourself, from first principles.
Use statistics and statistical methods to make decisions and predictions from data.
Recognize common misuses of statistics.
Topics roadmap#
Thinking about scale
Numbers are only meaningful in context.
Topics: Key questions to put numbers in context. Thinking about scale: comparisons, ballpark estimates, cost-benefit analysis.
Probability
A mathematical tool for reasoning about uncertainty.
The core logic that powers statistics
Topics: Coincidences, Bayes’ rule and conditioning, false positives in testing, decision making in the face of uncertainty
Exploratory data analysis
We collected some data. What can we learn from it?
Topics: Fundamental summary statistics (averages, variability, correlation), data visualization
Correlation and experiments
Using data to make reliable predictions.
Principles of experiments. Fundamentals of experimental design.
Topics: sampling and sample bias, polls, confidence intervals, hypothesis tests and p-values, correlation vs. causation
Machine learning
What are ML models? How do they work (and can we trust them)?
Topics: regression, model “training,” expressiveness of models
What to expect from this class#
The emphasis on this class will be on fundamental concepts and statistical thinking; I want you to feel enfranchised to think about data and statistics from first principles.
Formulas and memorization will be kept to a minimum.
Lectures: M,W,F. Each lecture includes an extra credit worksheet that you can hand in at the end of class.
Discussion section: Th. Discussion activities and “show and tell,” based on an extra credit assignment.
For this week: find an example in the news where numbers are presented out-of-context, and do your own independent ballpark estimate for what the number should be.
Readings: Each week there will be some reading (or watching/listening), meant to reinforce the concepts we see in class. There is no official course textbook. All lecture content will be posted online.
Quizzes: Every week on Friday, in-person. Study as you go! A practice quiz will be made available each Monday.
Final: In-person on June 9, 2025.
See the Syllabus for more details.